

In March 2026, we ran a blind pairwise evaluation of the four leading image models on a single job: product detail shots from a hero reference. The field: Seedream 5.0 Lite (ByteDance), Gemini 3 Pro Image Preview (Google), GPT Image 1.5 (OpenAI), and FLUX.2 [max] (Black Forest Labs).
The result
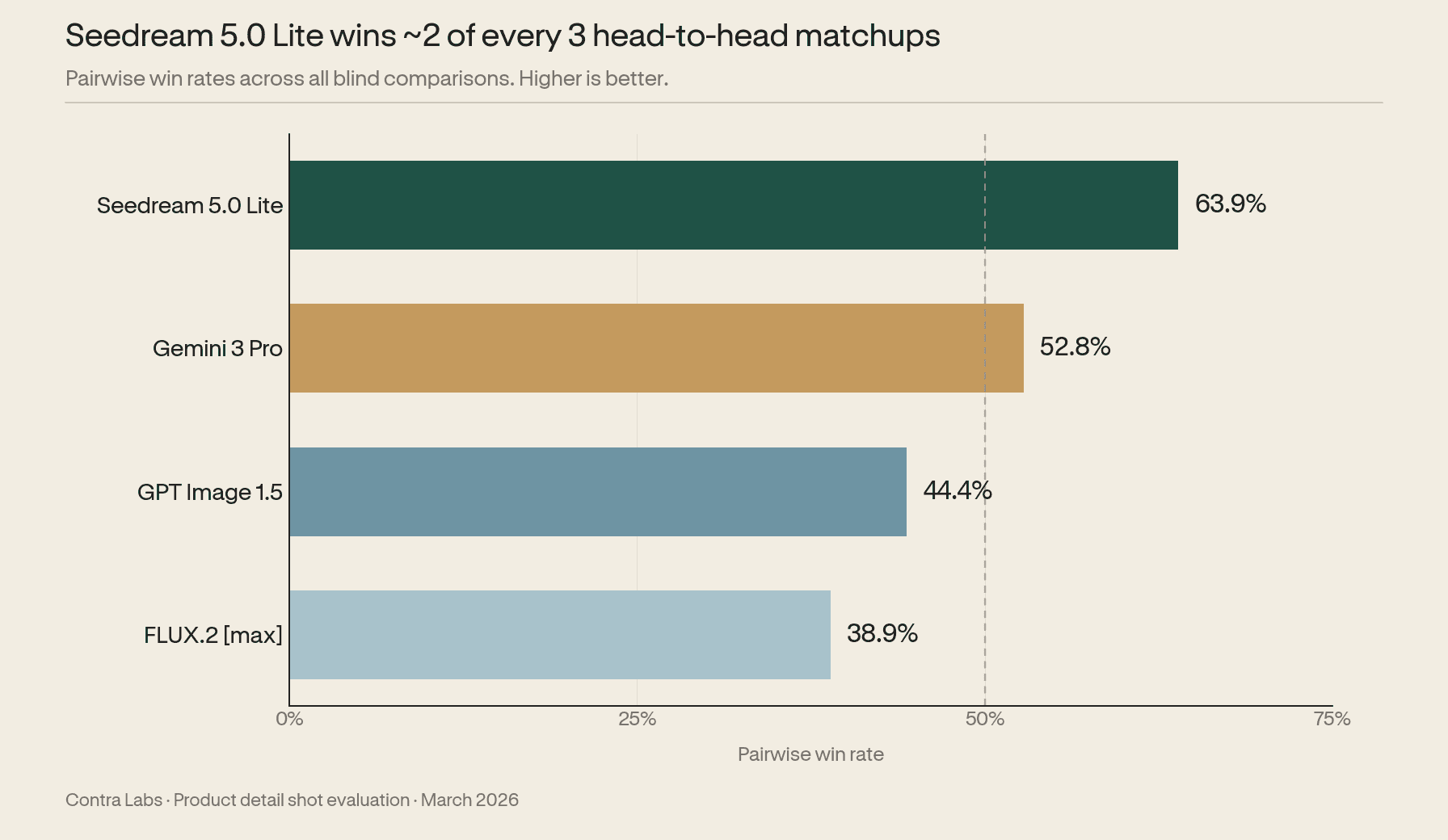
Seedream 5.0 Lite won 63.9% of all head-to-head matchups. Gemini 3 Pro followed at 52.8%. GPT Image 1.5 (44.4%) and FLUX.2 [max] (38.9%) both finished below the 50% line, losing more matchups than they won.
In Bradley-Terry Elo, Seedream landed at 1567 and Gemini 3 Pro followed at 1545. GPT Image 1.5 (1446) and FLUX.2 [max] (1442) were virtually tied at the bottom. A clean top and bottom tier with a ~120-point gap between them.

How we ran it
Professional creatives evaluated outputs from all four models, blind, against a real product reference (jewelry, leather goods, electronics, audio). Each evaluator ranked the outputs head-to-head and rated them across five scalar categories: lighting and shadows, color consistency, product detail handling, prompt adherence, and production-readiness. Models were the latest publicly available versions in March 2026.
No model names or watermarks. Bias removed at the evaluator's eye.
Seedream led every category we measured
Professional creatives rated each output across all five scalar categories. Seedream led all five.
Its top marks were in lighting and shadows (4.25 / 5) and color consistency (4.17 / 5). The widest gap between Seedream and the lowest-scoring model was in color consistency (1.09 points). The narrowest was in lighting and shadows (0.58). Even where the field tightened, Seedream stayed on top.
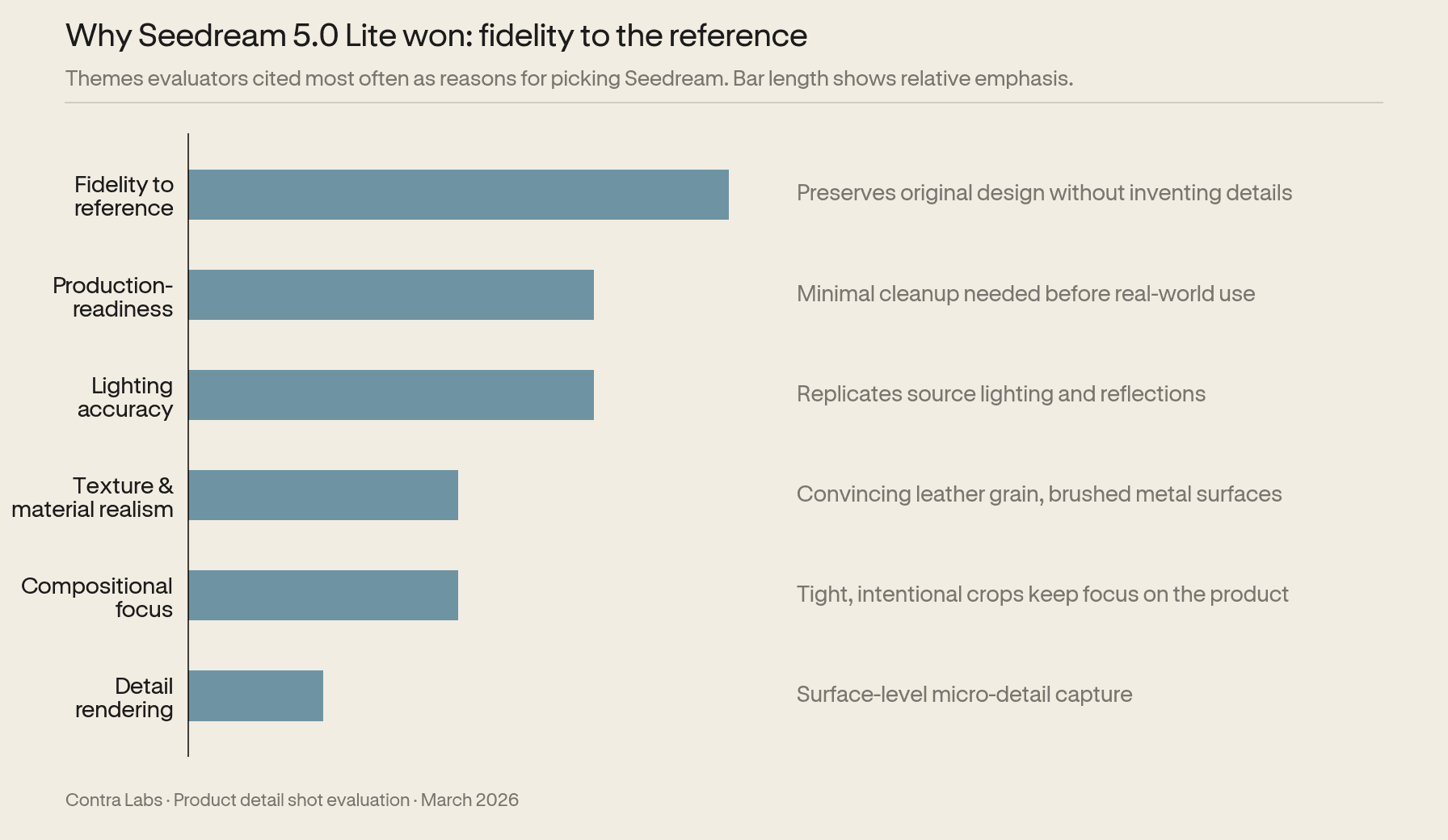
Why evaluators picked it: fidelity to the reference
The pattern in the rationales was consistent. Evaluators didn't pick Seedream because it was the prettiest. They picked it because it preserved the source.
Creative director Joao Paulo Bastos, on a handbag prompt:
Model C keeps the neutral background closer to the original, preserves the leather texture more accurately, and the clasp hardware reads truer to the reference image. That consistency with the input is what pushed it to first place for me, since the whole point of this task is evaluating how well the models maintain details from the source.Joao Paulo Bastos, creative director

Brand director Anna Gudvin, on a jewelry prompt where Seedream avoided embellishing details that weren't in the source:
The selected image maintained the original design without introducing additional milgrain detailing that was not present in the reference, preserving product integrity. It also replicated the lighting most accurately, with soft, diffused highlights and coherent reflections consistent with the hero image.Anna Gudvin, brand director

For product detail shots specifically, this is the right thing to optimize for. The output isn't a new image. It's a faithful zoom on an existing one. Inventing details, however tasteful, is a hard fail.
Where it lost
Seedream wasn't perfect. On a MacBook prompt, it ranked last. The issue was compositional focus.
Model C felt the least focused overall, with less control over where the viewer's attention goes.Joao Paulo Bastos, creative director

Worth flagging because the same evaluator picked Seedream first on the handbag prompt. The model is strong, but compositional control on tech products with hard edges and screens is an open weakness.
What this means
For catalog work, PDP imagery, and any use case where the output has to read as a continuation of the hero shot, Seedream 5.0 Lite is the strongest model we've tested. Its lead comes from a specific quality (fidelity to the reference) that matters more for product shots than aesthetic flourish does.
How we ran this study → Methodology